Un po’ di Bulldozer
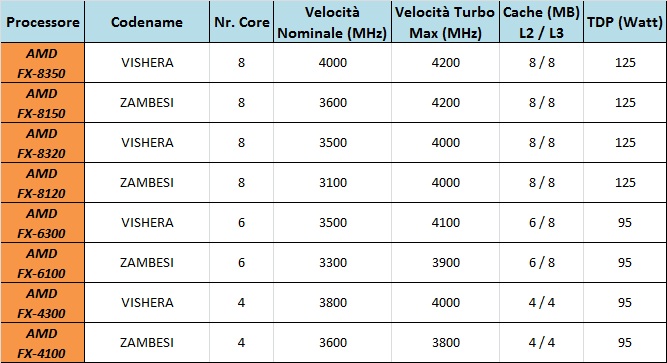
AMD ha mantenuto anche per Vishera la sigla FX, ma naturalmente l’architettura ha subito un miglioramento che ha permesso di mantenere sui modelli di punta sempre gli 8 core fisici totali e allo stesso tempo d’incrementare la frequenza di lavoro, il tutto agendo sempre sullo stesso processo produttivo a 32nm SOI delle industrie GlobalFoundries grazie ad un affinamento dello stesso. Come è facile intuire AMD è stata in grado, pur mantenendo lo stesso TDP, di aumentare le frequenze operative; merito di un’architettura estremamente efficiente. Possiamo fare una prima distinzione nella tabella seguente tra il core Bulldozer (Zambesi) precedente e Piledriver (Vishera).
AMD con il debutto della proprio progetto Bulldozer ha proposto per la prima volta un’architettura orientata a sistemi High-End, mentre dall’altra parte contrappone il progetto Bobcat che verrà adottato nelle proprie APU Brazos dove l’obiettivo principale è l’abbattimento dei consumi pur con un livello prestazionale di tutto rispetto. La nuova architettura Bulldozer in versione mobile in realtà non ha mai visto la luce se non con l’introduzione della APU della famiglia Trinity. L’architettura Bulldozer ha avuto il suo approccio nei sistemi Desktop, Server e Workstation.
Per capire meglio cosa c’è di diverso in Piledriver vediamo di richiamare l’architettura Bulldozer:
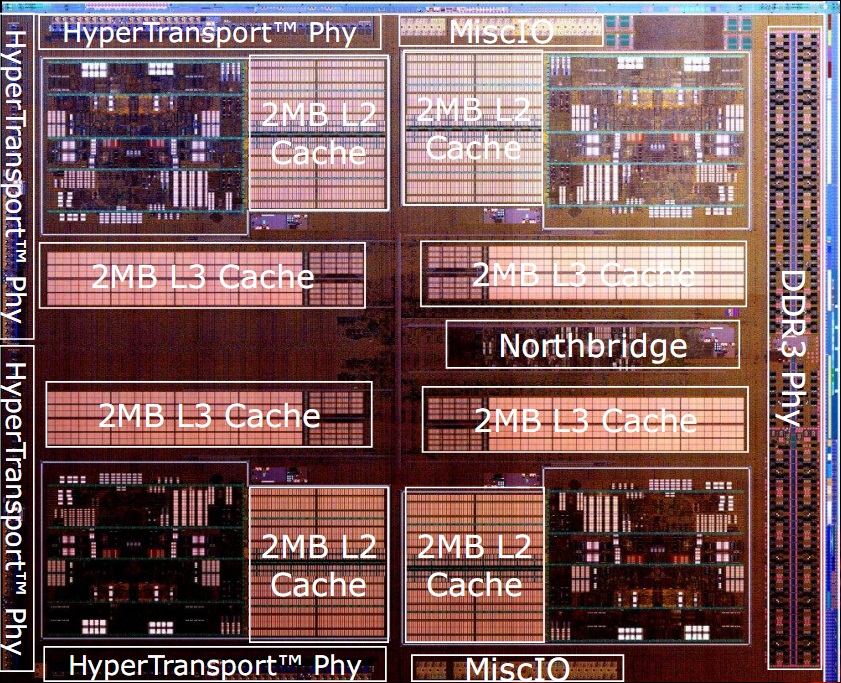

L’architettura del chip comprende quattro moduli, ognuno composto da due core e 2MB di cache L2 condivisa, un North Bridge che gestisce l’interconnessione tra tutti gli elementi del chip, una cache L3 condivisa da 8MB, un controller di memoria DDR3 dual channel e quattro controller HyperTransport, di cui uno solo attivo nelle CPU di classe desktop.
Lo scopo ultimo dei progettisti AMD era di massimizzare il rapporto performance per Watt, tenendo conto anche della superficie occupata. Questo è stato ottenuto in vari modi. Dall’analisi della letteratura è emerso che esiste una complessità ottimale della pipeline di un processore per avere il miglior rapporto performance per Watt.
Pipeline semplici e con un numero elevato di stadi consentono di avere clock alti, ma IPC (istruzioni per clock) bassi. Il consumo sale notevolmente all’aumentare del clock e quindi non si può innalzare troppo tale parametro, arrivando a un limite invalicabile sulle prestazioni.
Pipeline complesse e con pochi stadi sono più lente, ma hanno IPC elevati, bilanciando il clock più basso. Avendo un numero elevato di transistor, occupano più area del chip e consumano una parte superiore di energia in leakage (correnti di dispersione), dovuto al numero elevato di transistor. Questo si traduce anche in un’ulteriore limitazione per il clock massimo ottenibile.
La condizione ottimale è a metà strada tra questi due estremi ed è stato stabilito da vari studi teorici in letteratura. Un indice della complessità di una pipeline è il FO4, che indica quanto è il ritardo normalizzato di uno stadio di pipeline. Maggiore è questo numero, più complesso (e lento) è lo stadio della pipeline, e auspicabilmente meno stadi di pipeline sono necessari per implementare una data architettura.
Determinata la complessità ottimale della pipeline ora il problema è implementare la CPU con il minimo numero di transistor. Una delle cose che è stata fatta è la condivisione di tutte le unità sottoutilizzate. Questo è il motivo della nascita del modulo.
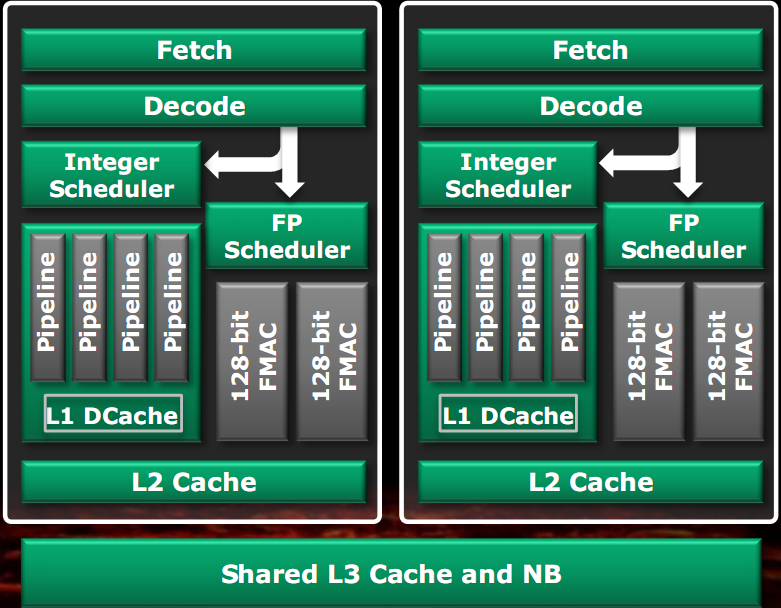
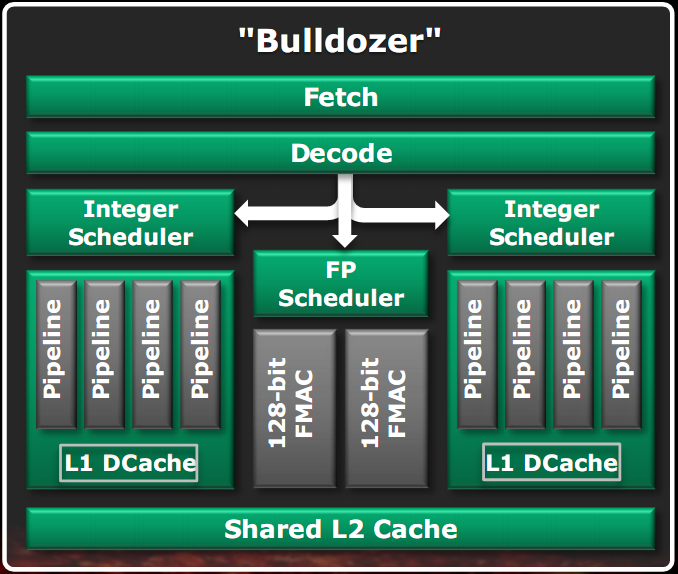
Nella figura di sinistra è visibile la classica implementazione di una CPU dual core, con la duplicazione della maggior parte delle componenti. Nella figura di destra è visibile uno schema a blocchi di un modulo Bulldozer.
Le unità che non sono utilizzate in pieno per la maggior parte del tempo sono state condivise tra i due core, potendo così anche renderle più potenti rispetto al caso di unità separate, poiché ora il budget di transistor si divide tra due core e quindi è possibile utilizzarne di più per una singola unità. Come visibile in figura, le unità condivise sono l’unità di fetch, l’unità di decodifica, l’unità Floating Point e la cache L2. Le cache L1 dati e le unità intere sono rimaste separate poiché si è stabilito che esse sono le unità più utilizzate di un core. Questo approccio consente di eseguire due thread con una velocità media pari all’80% rispetto al caso di core separati, in un’area di solo il 12% in più rispetto a quella di un singolo core (escludendo dal computo la cache L3, il North bridge e il controller RAM).
Abbassare il numero di transistor, abbassa il leakage e quindi consente clock più alti a parità di TDP. Ma per avere clock ancora più alti è necessario avere un risparmio energetico molto efficace. Le strategie implementate in Bulldozer sono le seguenti: clock gating estensivo delle reti logiche su tutto il die, ossia spegnimento del clock per le unità non utilizzate in un dato istante, power gating estensivo dei circuiti logici, ossia spegnimento anche dell’alimentazione elettrica per le unità non utilizzate in un dato istante, implementazione dello stato C6 di spegnimento dei moduli o dell’intero package, tramite anelli di transistor attorno alle unità, P-state di risparmio energetico o di turbo core, per avere in ogni istante il consumo ottimale in funzione del carico, caratteristica permessa dal modulo APM (advanced power management) che misura istante per istante il consumo del chip e determina il P-state ottimale, risparmio energetico dei moduli RAM ed infine stato di risparmio energetico C1E, in cui un core in idle consuma il meno possibile senza essere spento completamente.
Ultima caratteristica implementata in Bulldozer è il Turbo Core.

Il Turbo core si serve della unità APM per determinare quanto tempo la CPU può stare nel massimo stato di turbo possibile senza oltrepassare il consumo massimo stabilito. Quando sono utilizzati tutti i core, c’è quasi sempre qualche unità non utilizzata nel chip. L’unità APM calcola il budget di TDP e l’unità del turbo core, tramite un algoritmo di dithering, calcola quanto tempo la CPU può stare in stato di turbo senza oltrepassare il TDP. Se poi sono utilizzati la metà o meno dei core, lo stato di turbo utilizzabile prevede un clock ancor più elevato.